Promis à certains, voici le « comment ça marche un LLM » pour les nuls. Au programme : • Un LLM prend des mots en entrée et donne des mots en sortie. Nous, on va faire ça avec des chiffres. • On va simplifier un poil, mais tout sera suffisamment proche pour vous faire une idée.
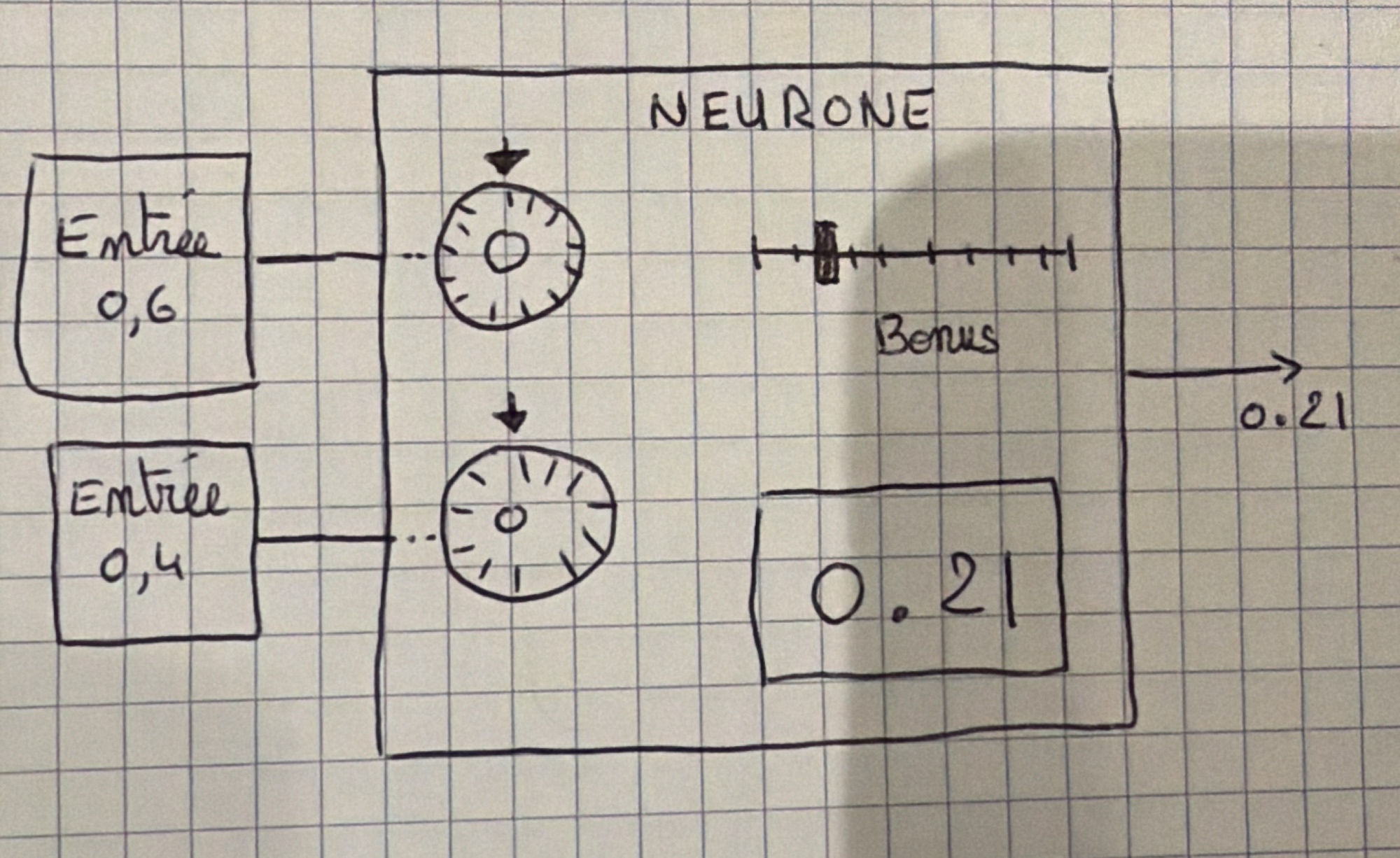
Le cœur d’un LLM, c’est un réseau de neurones artificiels. Du coup on va parler d’un neurone. Imaginez un neurone comme une petite boîte avec un écran affichant un nombre entre 0 et 1, et une sortie qui envoie ce résultat. En entrée, il y a des fils qui viennent d’autres neurones.
Avec chacun de ces fils il y a une molette : c’est pour faire entrer + ou – cette donnée : c’est le poids. Et on rajoute un slider pour rajouter un bonus. Le neurone va afficher [entrée1 × molette1 + entrée2 × molette2 + bonus] passé dans une moulinette qui va compacter le tout entre 0 et 1.
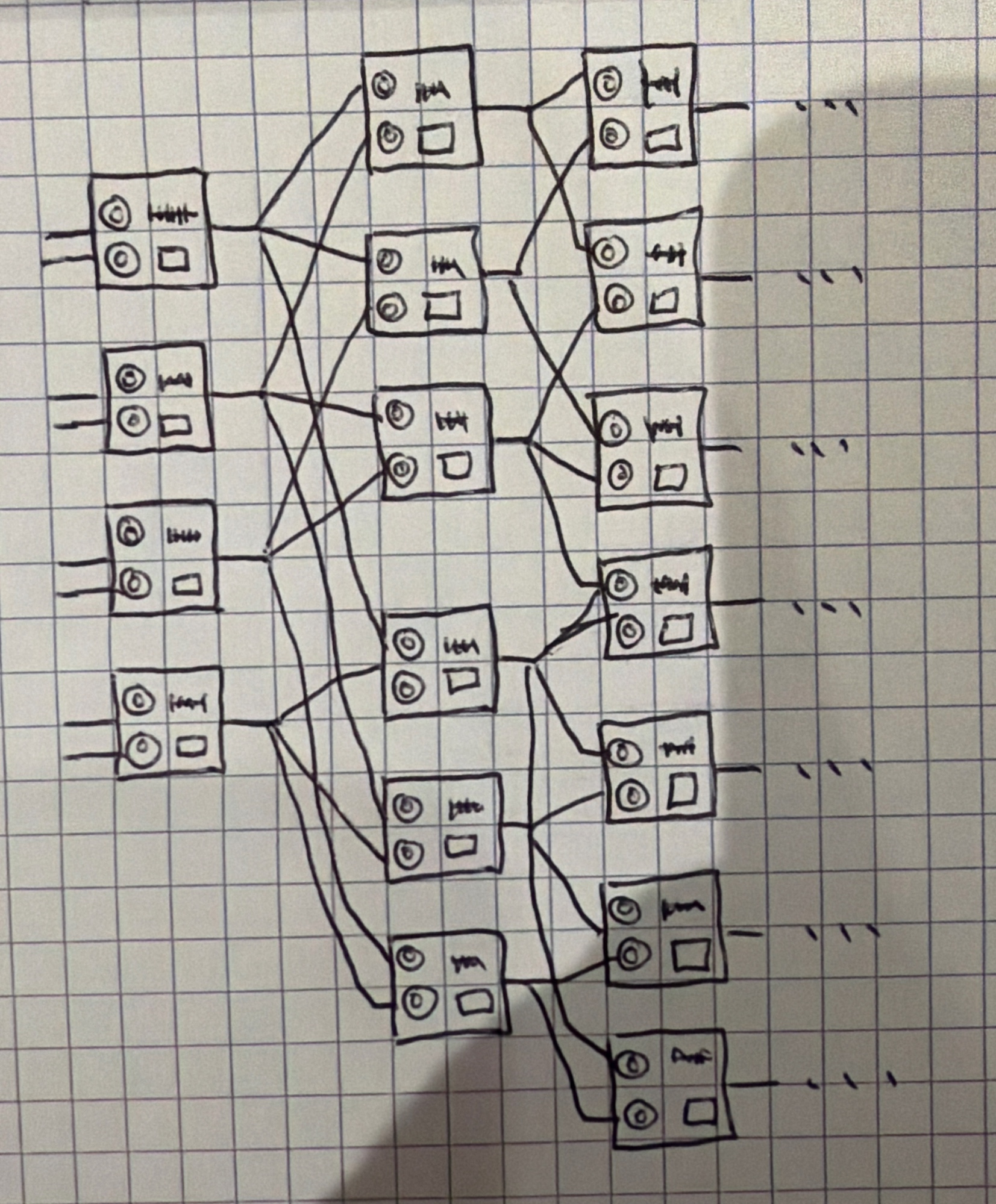
Il peut y avoir plus de deux entrées, on simplifie ici. Un réseau de neurones, ce sont juste des neurones connectés entre eux, en couches. Là j’ai 8 entrées, 3 couches, mais on peut en avoir un nombre beaucoup plus grand. La dernière couche, c’est la sortie.
Du coup comment ça marche. Imaginons qu’on veuille apprendre à notre système à prédire la suite d’un texte qui est « nombre + nombre = ». Exemple : 784 + 236 =… On va traduire ça en truc que les neurones peuvent comprendre. Genre si on dit qu’un signe c’est 1 et que chaque chiffre on le divise par 10, tout est entre 0 et 1, comme ce qu’aime un neurone. C’est parti !
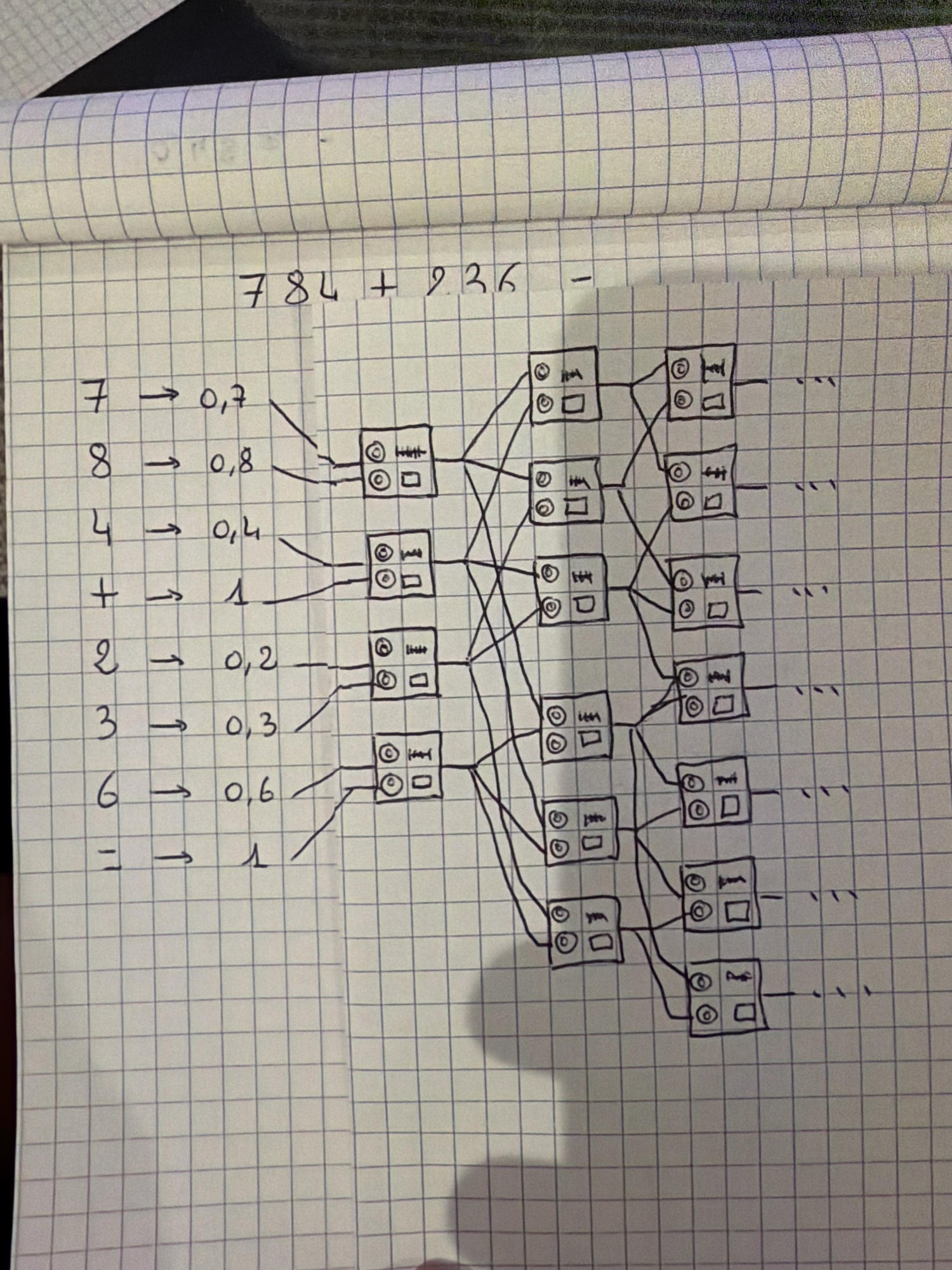
Le LLM va essayer de savoir quel est le prochain mot à sortir. Pour nous, le prochain chiffre. 784 + 236 = 1 020, donc il doit prédire 1. Du coup, en sortie il doit y avoir une plus forte probabilité que ce soit un 1. Mais ça peut sortir 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ou rien. On va attribuer un neurone de sortie par possibilité. Comme un neurone renvoie un nombre entre 0 et 1, ça sera la probabilité que ce soit ce résultat qu’il faut renvoyer ! C’est parti, on va pouvoir entraîner notre réseau de neurones !
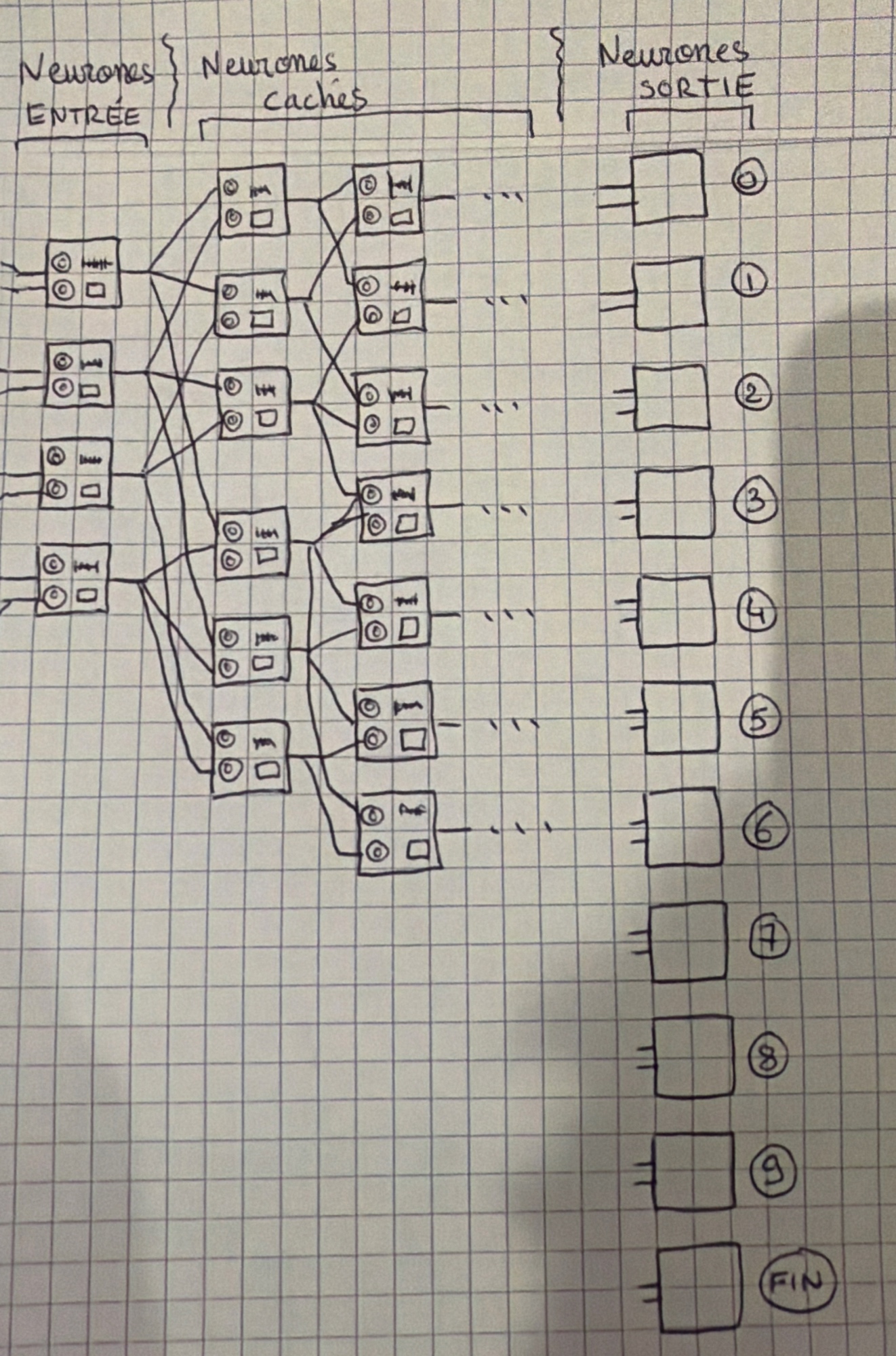
Donc première donnée. « 784 + 236 = » doit retourner 1. On met les bonnes entrées puis vous tournez les potards au hasard, vous bougez les sliders, comme un enfant de 8 mois (tout se joue à l’âge NeuralNetwork). Vous arrêtez quand vous voyez en sortie 1 très très possible (neurone à presque 1) et les autres très très impossibles (autres neurones à presque 0). Vous avez fait le premier apprentissage.
Le suivant : « 784 + 236 = 1 » en entrée. Bon, dans mon exemple il n’y avait pas assez de neurones, mais faisons comme si. Ceci dit ça vous explique pourquoi les LLM commencent à raconter n’importe quoi si la conversation est trop longue : ils en perdent des bouts. Bref, on met ça en entrée comme avant. En sortie, on devrait avoir en priorité un 0, parce que 784 + 236 = 1 0… et là vous allez tourner les bidules pour que le 0 soit plus prioritaire, mais en bougeant un peu petit à petit : il faut vérifier régulièrement que votre premier test continue de mettre « 1 » en priorité.
Ensuite vous mettez en entrée « 784 + 236 = 1 0 », la sortie doit avoir 2 en plus grande probabilité. Puis « 784 + 236 = 1 02 » et tourner les trucs pour 0 en sortie. Puis « 784 + 236 = 1 020 » et « FIN » en sortie. Notez dans tout ça que vous aurez changé tout au hasard jusqu’à ce que ça marche à peu près pour chaque exemple.
Avec suffisamment de neurones et de liens entre eux, ça ne sera pas parfait (1 en proba pour le bon nombre, 0 pour les autres), mais il y aura un réglage où tous les nombres qu’il faut seront le plus probables.
Bon, vous faites ça avec plein d’additions. Plein plein plein. Et une fois que c’est fait vous ne touchez plus à aucun neurone. C’est prêt. Maintenant, un tech-bro vous dira que pour n’importe quelle addition mise en entrée le résultat en sortie sera le bon. TRUST ME, si je lui ai donné suffisamment d’additions en entraînement, ça va diminuer les fois où il renverra n’importe quoi.
Sauf que là ce sont des maths. Il y a UNE bonne réponse. Mais dans une conversation ? Eh bien le LLM ne va pas renvoyer la réponse à plus forte probabilité. Le LLM va renvoyer une de ses X possibilités les plus probables, en fonction de cette probabilité. Donc déjà les probabilités qu’un mot soit mis en avant dépendent de roues crantées tournées au hasard par la machine, mais c’est même pas le plus probable de tout ça qui va sortir.
Alors attention : ça n’a pas l’air intuitif, mais les résultats en question sont très précis, ça marche très bien, vous le vivez tous les jours. Parce qu’il y a BEAUCOUP de neurones et BEAUCOUP de couches. Mais vous voyez que ce n’est pas « s’il a lu ce mot X fois alors il a plus de chances de le sortir ». La réponse d’un LLM n’est pas une probabilité liée aux données d’entraînement. Et c’est le cœur de l’hallucination.
Les LLM ne répètent pas ce qu’ils ont lu : les réglages (des millions) de chaque neurone dépendent de l’ENSEMBLE du corpus d’entraînement. Avoir une info qui a été répétée dans le corpus ne change pas obligatoirement le résultat tant que ça à la fin. Ou peut-être si. On sait pas.
Un LLM est un poil plus compliqué qu’un simple réseau de neurones comme celui-ci, mais la différence principale c’est un autre groupe de neurones qui va regarder comment chaque mot en entrée contextualise les autres mots pour changer les valeurs qui vont entrer au début. (Par ailleurs, vos réponses elles-mêmes changent les réglages de chaque neurone si le modèle est en apprentissage continu.) (Mais le cœur de comment ça marche reste.)
Voilà voilà. Pardon encore pour les spécialistes qui vont voir quelques simplifications abusives. Et bisous.
Fun fact. Les potentiomètres et les sliders, là, j’ai fait exprès de ne pas en donner d’ordre de grandeur. Bon, bah ChatGPT 5, c’est aux alentours de 1000 milliards.
Peut-être que je vous parlerai un jour de rétropropagation : c’est, pendant l’entraînement, l’algorithme qu’on utilise pour tourner tous ces boutons des neurones ; on ne le fait pas complètement au hasard en vrai. Mais c’est technique pour pas grand-chose donc pas sûr.